Las librerías en programación son colecciones de código predefinido que contienen funciones, clases y métodos diseñados para realizar tareas específicas, facilitando el desarrollo de software al evitar que los programadores deban escribir todo el código desde cero. En el contexto de la ciencia de datos y el machine learning, las librerías juegan un papel crucial, ya que proporcionan herramientas optimizadas para manejar, procesar y analizar grandes volúmenes de datos, así como para crear y entrenar modelos predictivos. Estas librerías permiten desde la carga y manipulación de datos (como con Pandas y NumPy), hasta la visualización (con Matplotlib y Seaborn) y el modelado predictivo (con Scikit-Learn y TensorFlow).
Cada librería en este campo está diseñada para abordar aspectos específicos y complejos del análisis de datos, lo cual hace que la ciencia de datos sea más accesible, efectiva y eficiente. Además, muchas de estas librerías están respaldadas por comunidades de desarrolladores y científicos que las mantienen y mejoran constantemente, asegurando que sigan siendo relevantes y funcionales en un campo tan dinámico. En resumen, las librerías en ciencia de datos y machine learning son herramientas fundamentales que simplifican tareas repetitivas, optimizan el rendimiento y ayudan a los analistas y científicos de datos a lograr resultados precisos y útiles en sus proyectos.
Ejemplo de uso de Libreria
ejemplo sencillo usando la librería Pandas en Python, que es fundamental en ciencia de datos para manipulación y análisis de datos en formato de tablas o dataframes. Este código demostrará cómo cargar un archivo CSV, visualizar sus primeras filas, filtrar datos y realizar algunas operaciones básicas.
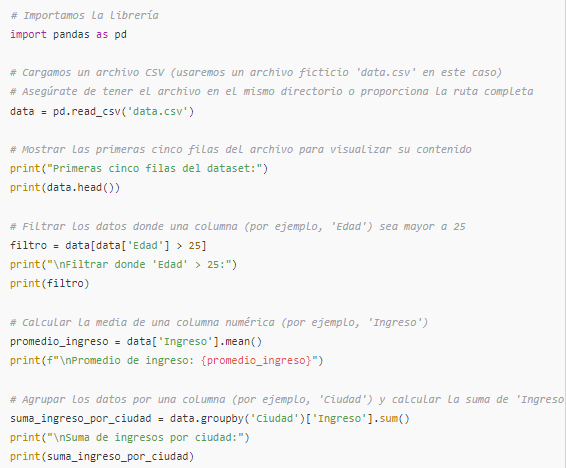
Explicación del Código:
- Importación de la librería: Importamos Pandas con
import pandas as pd. - Cargar el archivo CSV: Usamos
pd.read_csv()para cargar los datos de un archivo CSV y guardarlos en un dataframe llamadodata. - Visualización de datos: Con
data.head()mostramos las primeras cinco filas del dataset, lo que es útil para obtener una vista general. - Filtrar datos: Usamos
data[data['Edad'] > 25]para filtrar el dataframe, mostrando solo las filas donde la columna ‘Edad’ es mayor a 25. - Cálculo de la media:
data['Ingreso'].mean()calcula el promedio de los valores en la columna ‘Ingreso’. - Agrupación y agregación:
data.groupby('Ciudad')['Ingreso'].sum()agrupa los datos por la columna ‘Ciudad’ y calcula la suma de la columna ‘Ingreso’ para cada ciudad.
Este es solo un ejemplo básico, pero muestra cómo una librería como Pandas permite realizar operaciones complejas en pocas líneas de código, facilitando el análisis de datos.
Principales Librerias Usadas en Ciencia de Datos y Machine Learning
1. NumPy
- Descripción: Es la base para muchas operaciones de cálculo y manipulación de datos en ciencia de datos.
- Funciones: Manejo de arreglos y matrices de grandes volúmenes de datos numéricos. Proporciona funciones para realizar operaciones matemáticas rápidas y eficientes.
2. Pandas
- Descripción: Biblioteca esencial para la manipulación y análisis de datos estructurados.
- Funciones: Facilita la lectura, transformación y manipulación de datos en formatos como tablas, hojas de cálculo, y series temporales. Utiliza estructuras de datos como
DataFramespara manejar grandes volúmenes de datos.
3. Matplotlib
- Descripción: Librería de visualización de datos, ampliamente utilizada para gráficos básicos.
- Funciones: Permite crear gráficos como líneas, barras, histogramas y dispersión. Es muy personalizable y útil para visualizaciones estáticas.
4. Seaborn
- Descripción: Extensión de Matplotlib que facilita la creación de gráficos estadísticos.
- Funciones: Simplifica la visualización de patrones y relaciones en los datos. Permite crear gráficos avanzados como mapas de calor, gráficos de distribución, y gráficos de correlación con menos código.
5. Scikit-Learn
- Descripción: Una de las bibliotecas más completas para machine learning en Python.
- Funciones: Contiene algoritmos para clasificación, regresión, clustering, reducción de dimensionalidad y preprocesamiento de datos. Además, proporciona herramientas para validación cruzada y ajuste de hiperparámetros.
6. TensorFlow
- Descripción: Biblioteca desarrollada por Google para deep learning y redes neuronales.
- Funciones: Ideal para construir, entrenar y desplegar modelos de redes neuronales complejas, especialmente en tareas de visión por computadora, procesamiento de lenguaje natural y reconocimiento de voz.
7. Keras
- Descripción: API de alto nivel construida sobre TensorFlow que facilita la creación de modelos de redes neuronales.
- Funciones: Permite construir modelos de deep learning con pocas líneas de código. Ideal para principiantes en redes neuronales.
8. PyTorch
- Descripción: Biblioteca de deep learning desarrollada por Facebook, muy utilizada en investigación.
- Funciones: Ofrece una gran flexibilidad para el diseño y entrenamiento de redes neuronales. Facilita la construcción de modelos de aprendizaje profundo, y es popular por su modo dinámico de cálculo de gráficos computacionales.
9. Statsmodels
- Descripción: Biblioteca para el análisis estadístico en Python.
- Funciones: Proporciona herramientas para realizar pruebas estadísticas, modelos de regresión y análisis de series temporales. Es ideal para proyectos de análisis de datos más orientados a la estadística.
10. NLTK (Natural Language Toolkit)
- Descripción: Biblioteca especializada en procesamiento de lenguaje natural (NLP).
- Funciones: Proporciona herramientas para trabajar con texto, realizar análisis gramatical, etiquetado de palabras, análisis de sentimientos y modelos de lenguaje.
11. SpaCy
- Descripción: Otra biblioteca para procesamiento de lenguaje natural, centrada en aplicaciones de NLP de producción.
- Funciones: Permite el análisis sintáctico, reconocimiento de entidades y otras tareas avanzadas de procesamiento de texto. Es rápida y se utiliza mucho en aplicaciones comerciales de NLP.
12. Gensim
- Descripción: Biblioteca para modelado de tópicos y procesamiento semántico.
- Funciones: Se utiliza principalmente para trabajar con grandes cantidades de texto y para realizar modelado de temas (topic modeling) y representación de palabras mediante técnicas como Word2Vec.
13. XGBoost
- Descripción: Implementación avanzada de árboles de decisión basada en boosting.
- Funciones: Es una de las herramientas más efectivas para problemas de clasificación y regresión en competencias de machine learning. Destaca por su alta precisión y rendimiento en grandes volúmenes de datos.
14. LightGBM
- Descripción: Otra biblioteca de boosting para árboles de decisión, desarrollada por Microsoft.
- Funciones: Está diseñada para un entrenamiento más rápido y eficiente en memoria, y es ideal para trabajar con grandes volúmenes de datos.
15. CatBoost
- Descripción: Algoritmo de boosting optimizado para el uso en machine learning.
- Funciones: Es especialmente eficaz en el manejo de variables categóricas y es utilizado en tareas de clasificación y regresión. Desarrollado por Yandex, ha ganado popularidad en competencias de machine learning.
16. OpenCV
- Descripción: Biblioteca de procesamiento de imágenes y visión por computadora.
- Funciones: Facilita el trabajo con imágenes y videos, permitiendo tareas como detección de bordes, filtros, reconocimiento de rostros y análisis de movimiento.
17. Plotly
- Descripción: Biblioteca de visualización de datos interactiva.
- Funciones: Permite crear gráficos interactivos y complejos, útiles para presentaciones y dashboards. Ideal para mostrar datos en tiempo real.
18. Dash
- Descripción: Biblioteca para construir aplicaciones web interactivas en Python.
- Funciones: Permite crear aplicaciones web para ciencia de datos, facilitando la visualización interactiva de datos. Es desarrollada por Plotly y es ideal para construir dashboards sin necesidad de conocimientos avanzados de desarrollo web.
19. BeautifulSoup
- Descripción: Herramienta para web scraping en Python.
- Funciones: Facilita la extracción de datos de páginas HTML y XML, comúnmente usada para obtener datos de sitios web.
20. Scrapy
- Descripción: Marco para web scraping que permite extraer, procesar y almacenar datos de páginas web.
- Funciones: Es más potente que BeautifulSoup para proyectos grandes y estructurados de extracción de datos web.
21. Time Series Analysis (TSFresh)
- Descripción: Biblioteca para el análisis de series temporales.
- Funciones: Extrae características de series temporales, lo que es útil para modelos de predicción basados en patrones de tiempo.
22. H2O.ai
- Descripción: Plataforma para machine learning escalable.
- Funciones: Ofrece modelos de machine learning y deep learning que se ejecutan en múltiples nodos, ideal para tareas de big data y análisis de grandes volúmenes de datos en tiempo real.
23. Orange3
- Descripción: Plataforma visual para análisis de datos y machine learning.
- Funciones: Permite crear flujos de trabajo visuales para machine learning sin programar, ideal para principiantes o para crear prototipos rápidos.
24. MLflow
- Descripción: Plataforma de código abierto para la gestión de flujos de trabajo en machine learning.
- Funciones: Permite la gestión y seguimiento de experimentos, facilitando el control de versiones, despliegue y escalabilidad de modelos en producción.
25. Dask
- Descripción: Herramienta para la computación paralela en Python.
- Funciones: Permite manejar grandes volúmenes de datos distribuyendo las operaciones en múltiples procesos o máquinas. Es útil para ampliar las capacidades de Pandas en entornos de big data.

