Los conjuntos son especialmente útiles en el análisis de datos y el machine learning para varias tareas relacionadas con la limpieza de datos, duplicación, y comparación de características. Aquí te doy algunos ejemplos de casos reales donde los conjuntos pueden ser de gran ayuda.
Eliminar duplicados en una columna de datos
Cuando trabajas con datos, es común encontrarse con duplicados en una columna que representa categorías o nombres. Los conjuntos pueden ayudarte a identificar los valores únicos rápidamente y limpiar los datos para evitar redundancias.
Ejemplo: Imagina que tienes una lista de nombres de productos en una columna y deseas ver todas las categorías únicas de productos sin duplicados.

Este método es rápido y fácil para ver todas las categorías únicas sin tener que buscar y eliminar duplicados manualmente.
Detección de valores únicos en conjuntos de datos grandes
En datasets de gran tamaño, es común encontrarse con valores inconsistentes en las columnas. Por ejemplo, en análisis de texto, puedes usar conjuntos para obtener el vocabulario único en una columna de textos, lo que es útil en técnicas de Procesamiento de Lenguaje Natural (NLP).
Ejemplo: Imagina que tienes una columna de comentarios de usuarios, y deseas saber todas las palabras únicas usadas en los comentarios para crear un vocabulario básico.

Este conjunto vocabulario te proporciona todas las palabras únicas que aparecen en los comentarios, que puede ser el primer paso para crear un modelo de Bolsa de Palabras (Bag of Words) en NLP.
Identificación de columnas con valores comunes entre dos datasets
En análisis de datos y machine learning, a veces es necesario combinar o comparar datasets. Los conjuntos son útiles cuando deseas ver si hay valores comunes en dos columnas de diferentes conjuntos de datos, como ID de usuarios o nombres de productos.
Ejemplo: Supón que tienes dos datasets: uno con clientes que han realizado compras y otro con clientes que han dejado una reseña. Te interesa encontrar los clientes que han hecho ambas cosas.

Este resultado muestra los clientes que tanto compraron como dejaron una reseña, lo cual puede ser útil para análisis de comportamiento de clientes.
Identificar variables que no están en dos conjuntos de datos diferentes
En ciencia de datos, cuando trabajas con dos datasets que deberían tener los mismos tipos de variables o categorías, puedes usar conjuntos para verificar que ambos conjuntos de datos tienen las mismas características o para encontrar diferencias en las categorías.
Ejemplo: Imagina que tienes dos versiones de un dataset de ventas y quieres asegurarte de que ambos tienen las mismas categorías de productos.

En este caso, solo_2023 y solo_2024 contienen las categorías exclusivas de cada dataset, lo cual puede ayudarte a identificar inconsistencias o nuevas categorías en los datos.
Detección de valores que faltan en un conjunto de datos
Cuando trabajas con variables categóricas en machine learning, a veces es importante asegurarte de que todos los posibles valores están representados. Por ejemplo, en un dataset de datos demográficos, podrías querer asegurarte de que tienes todos los países en una lista de clientes.
Ejemplo: Imagina que tienes un conjunto de países a nivel mundial y un conjunto de países representados en los datos de tu empresa. Usar un conjunto puede ayudarte a detectar los países que no están representados.

Resumen
Estos son algunos ejemplos donde los conjuntos son útiles en el análisis de datos y machine learning:
- Eliminar duplicados en listas de datos.
- Identificar valores únicos (como palabras en NLP).
- Comparar listas o columnas de datos para encontrar elementos comunes o exclusivos.
- Verificar consistencia en categorías entre datasets.
- Detectar valores faltantes en un dataset categórico.
Ejemplo Practico en Google Colab
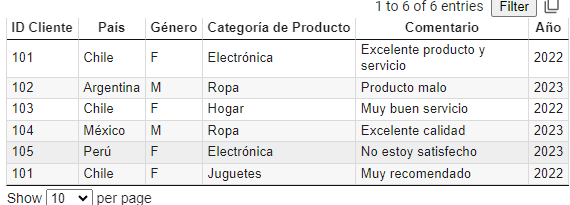
Trabajaremos con el sguiente Dataset que se puede descargar aqui
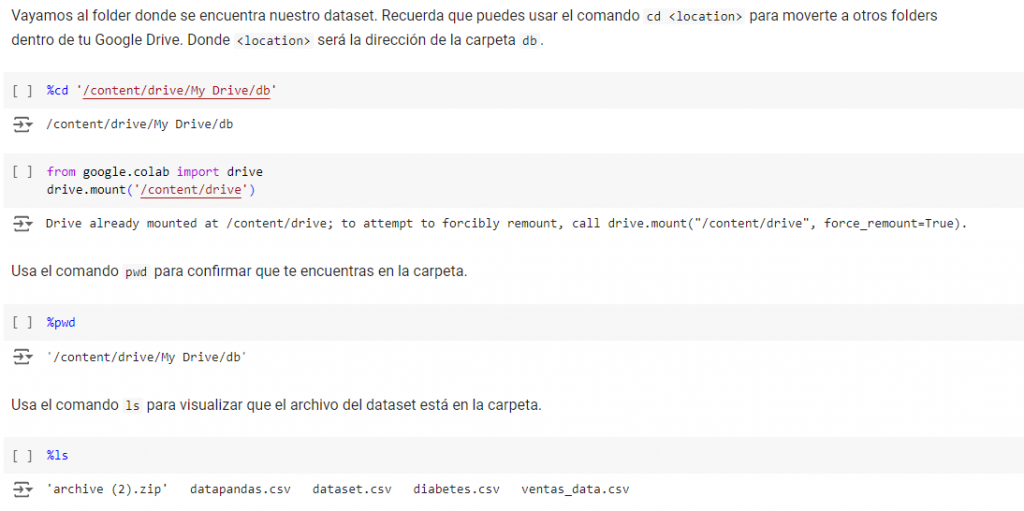
Primero damos acceso al sistema de archivo, en mi caso Google Drive en Carpeta llamada «db»
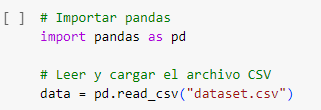
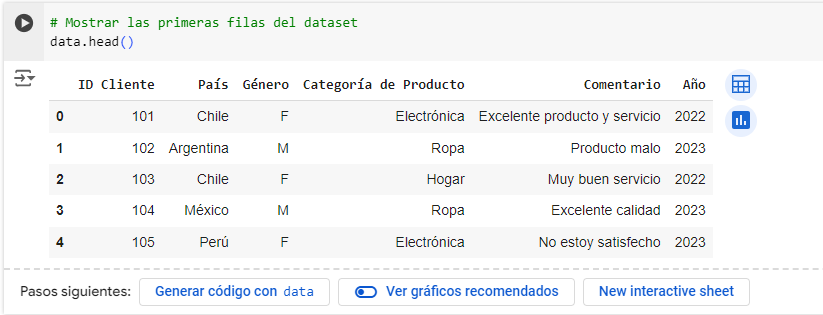
data.head()
data.head() es una función en pandas que se utiliza para mostrar las primeras filas de un DataFrame. Es una herramienta muy útil para explorar y verificar rápidamente el contenido de tus datos después de cargarlos en Python.
Parámetros de data.head()
head() acepta un parámetro opcional n que especifica el número de filas a mostrar. Por ejemplo:
data.head(10): muestra las primeras 10 filas del DataFrame.data.head(1): muestra solo la primera fila del DataFrame.
Si no pasas ningún valor, head() usará el valor predeterminado n=5 para mostrar las primeras cinco filas.
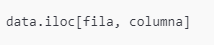
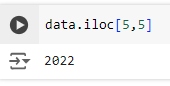
data.iloc[]
data.iloc[] es un método en pandas que se utiliza para acceder a filas y columnas en un DataFrame usando índices numéricos (posiciones) en lugar de nombres de etiquetas. Es una herramienta poderosa y flexible que permite seleccionar datos específicos por su posición en el DataFrame.
¿Cómo funciona data.iloc[]?
El método .iloc[] permite seleccionar elementos usando índices enteros (de ahí el nombre «integer-location based indexing»). Con data.iloc[], puedes acceder a:
- Filas específicas
- Columnas específicas
- Filas y columnas específicas al mismo tiempo
La sintaxis básica de data.iloc[] es:
Convertir la columna «ID Cliente» en un conjunto para identificar duplicados
- Extrae los IDs de cliente como una lista.
- Convierte esa lista en un conjunto.
- Compara la longitud de la lista original con la longitud del conjunto. Si son iguales, no hay duplicados; si son diferentes, existen duplicados.
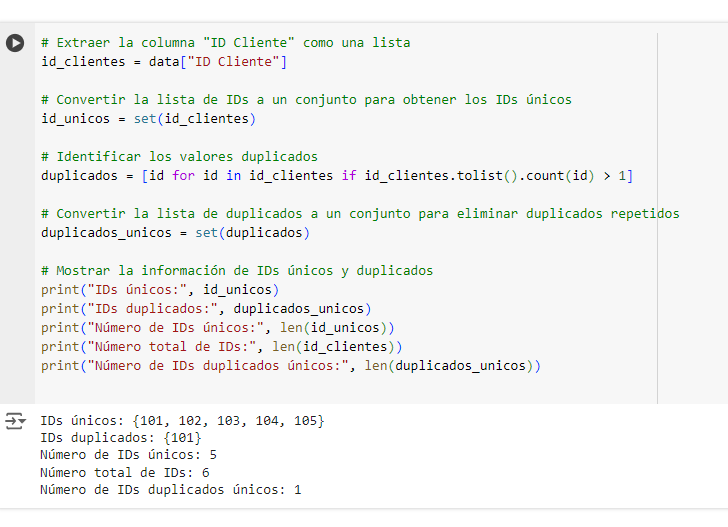
Explicación del código:
id_unicos = set(id_clientes): Esto convierte la lista de IDs a un conjunto, eliminando duplicados y mostrando los IDs únicos.duplicados = [id for id in id_clientes if id_clientes.tolist().count(id) > 1]: Este es un método para identificar los valores duplicados en la lista original.duplicados_unicos = set(duplicados): Convierte la lista de duplicados en un conjunto para que solo muestre cada ID duplicado una vez.
Nota:

Explicación Paso a Paso
- Lista de comprensión:
- Este código utiliza una lista de comprensión, que es una forma concisa de crear una lista en Python. Todo el bloque entre corchetes
[]genera una nueva lista de elementos que cumplen cierta condición.
- Este código utiliza una lista de comprensión, que es una forma concisa de crear una lista en Python. Todo el bloque entre corchetes
id for id in id_clientes:- Esto significa «para cada
idenid_clientes«, dondeid_clienteses una Serie de pandas que contiene los valores de la columna «ID Cliente». idrepresenta cada valor individual (ID) dentro deid_clientesmientras se recorre.
- Esto significa «para cada
if id_clientes.tolist().count(id) > 1:- Esta es la condición que se debe cumplir para que un
idsea añadido a la lista deduplicados. id_clientes.tolist()convierte la Serieid_clientesa una lista de Python, ya que las listas en Python tienen el método.count()que cuenta la cantidad de veces que un valor específico aparece.id_clientes.tolist().count(id)cuenta cuántas veces aparece elidactual en la lista.if ... > 1: Solo añade elida la lista deduplicadossi aparece más de una vez (es decir, si está duplicado).
- Esta es la condición que se debe cumplir para que un
Ejemplo de cómo funciona
Supongamos que id_clientes contiene los valores [101, 102, 103, 101, 104, 105]. Aquí está el desglose del código:
- Recorrido:
- Se evalúa cada
idenid_clientes:101,102,103,101,104,105.
- Se evalúa cada
- Condición:
- Para cada
id, se cuenta cuántas veces aparece enid_clientes:101: aparece 2 veces → se agrega aduplicados102: aparece 1 vez → no se agrega103: aparece 1 vez → no se agrega101: aparece 2 veces (otra vez) → se agrega aduplicados(otra vez)104: aparece 1 vez → no se agrega105: aparece 1 vez → no se agrega
- Para cada
- Resultado:
- La lista
duplicadosserá[101, 101](porque101aparece dos veces enid_clientes).
- La lista
Para obtener los IDs duplicados únicos, después de esta línea puedes convertir duplicados en un conjunto: duplicados_unicos = set(duplicados), lo cual eliminará las repeticiones y mostrará solo un 101.
Nota 2
La función len() en Python se utiliza para obtener el número de elementos en una estructura de datos, como una lista, conjunto, tupla, diccionario, cadena, entre otros.
En el contexto del código que has mostrado, len(id_unicos) cuenta la cantidad de elementos en el conjunto id_unicos, lo que nos da el número de IDs únicos en la columna «ID Cliente».
Agregar Nuevos Valores unicos a una columna
Supongamos que quieres asegurarte de que una columna solo contenga valores únicos. Podemos agregar nuevos valores a esa columna, verificando primero que no existan en los valores actuales para evitar duplicados.
Por ejemplo, en la columna "ID Cliente", podemos intentar agregar nuevos IDs de clientes y verificar si son únicos antes de agregarlos.
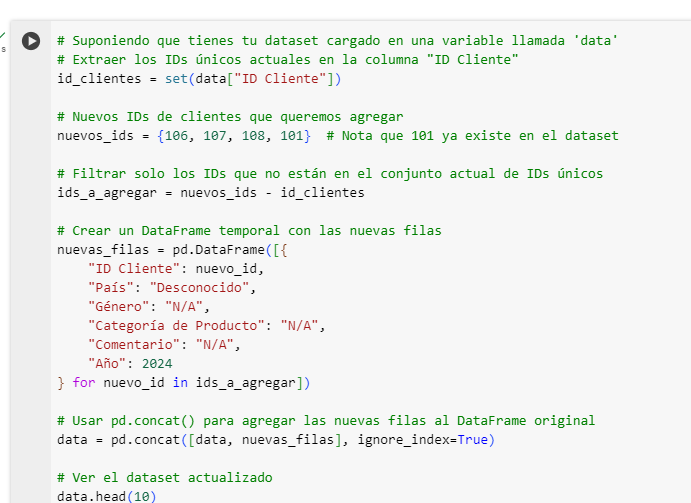
Explicacion del codigo:
Paso 1: Extraer los IDs únicos actuales
Primero, extraemos los IDs de cliente únicos que ya existen en el DataFrame data para asegurarnos de no duplicarlos.

data["ID Cliente"]selecciona la columna «ID Cliente» del DataFrame.
set(data["ID Cliente"])convierte la columna en un conjunto, eliminando automáticamente cualquier ID duplicado.
id_clientesahora contiene solo los IDs únicos en el dataset actual.
Paso 2: Definir los nuevos IDs que queremos agregar
Creamos un conjunto con los nuevos IDs de clientes que queremos agregar. Estos incluyen tanto IDs nuevos como uno que ya existe en el dataset (101).

Paso 3: Filtrar solo los IDs que no están en el dataset actual
Para asegurarnos de que solo estamos agregando IDs nuevos, calculamos la diferencia de conjuntos entre nuevos_ids y id_clientes. Esto nos dará solo los IDs que no existen en id_clientes.

nuevos_ids - id_clientesdevuelve un conjunto que contiene solo los elementos que están ennuevos_idspero no enid_clientes.
ids_a_agregarcontendrá solo los nuevos IDs{106, 107, 108}, excluyendo el101que ya existe endata.
Paso 4: Crear un DataFrame temporal con las nuevas filas
En este paso, creamos un DataFrame temporal nuevas_filas que contiene las nuevas filas que queremos agregar al dataset original.

- La lista de comprensión
[ {...} for nuevo_id in ids_a_agregar]crea una lista de diccionarios, donde cada diccionario representa una nueva fila para el Data Frame. - Cada diccionario tiene:
"ID Cliente"con unnuevo_iddeids_a_agregar."País","Género","Categoría de Producto","Comentario"y"Año"con valores ficticios como «Desconocido», «N/A», etc.
pd.DataFrame([...])convierte esta lista de diccionarios en un nuevo DataFramenuevas_filas, que tiene una fila por cada nuevo ID.
Paso 5: Combinar el DataFrame original con el DataFrame temporal
Usamos pd.concat() para combinar el DataFrame original data con el DataFrame nuevas_filas en uno solo.

pd.concat([data, nuevas_filas])concatena los dos DataFrames en un solo DataFrame.dataes el DataFrame original ynuevas_filascontiene las filas nuevas.
ignore_index=True: Esta opción reinicia los índices en el DataFrame resultante, asegurando que los índices sean consecutivos y que los nuevos datos no conserven los índices originales.
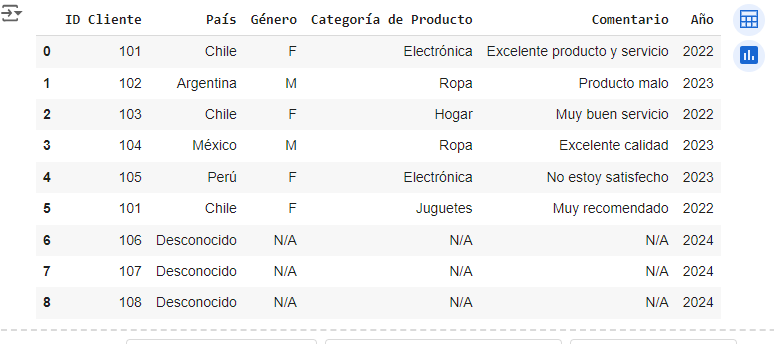
Paso 6: Verificar el dataset actualizado
Finalmente, mostramos las primeras filas del DataFrame para confirmar que las nuevas filas se han agregado correctamente.

Unión de dos conjuntos de datos
Supongamos que tienes otro conjunto de datos con nuevos registros de clientes y quieres combinarlos con el dataset existente, evitando duplicados en la columna "ID Cliente".
Imaginemos que data_nuevo es un nuevo DataFrame con los mismos campos.

Explicacion del codigo
Paso 1: Importar pandas y crear un DataFrame de ejemplo
Primero, importamos la biblioteca pandas y creamos un nuevo DataFrame data_nuevo que contiene algunos datos nuevos para agregar a un dataset existente.

data_nuevocontiene:- Tres nuevos clientes con IDs
105,109y110. - Cada cliente tiene datos sobre su país, género, categoría de producto, comentario y año.
- Tres nuevos clientes con IDs
- Este DataFrame servirá como el conjunto de datos que queremos agregar al dataset existente llamado
data.
Paso 2: Convertir los IDs de ambos datasets en conjuntos
A continuación, convertimos los IDs de cliente en ambos datasets (data y data_nuevo) a conjuntos para identificar cuáles son únicos y cuáles se repiten.
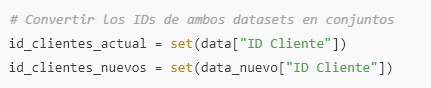
set(data["ID Cliente"])convierte la columna"ID Cliente"dedata(el dataset original) en un conjuntoid_clientes_actual, eliminando automáticamente duplicados.set(data_nuevo["ID Cliente"])convierte la columna"ID Cliente"dedata_nuevo(el nuevo dataset) en un conjuntoid_clientes_nuevos.- Al trabajar con conjuntos, podemos realizar operaciones de conjuntos como la diferencia y la intersección para identificar IDs que sean únicos o compartidos.
Paso 3: Encontrar los IDs únicos en el nuevo dataset
Aquí usamos la diferencia de conjuntos para encontrar los IDs que están en data_nuevo pero no en data. Estos son los IDs que necesitamos agregar, ya que no están presentes en el dataset original.

id_clientes_nuevos - id_clientes_actualdevuelve un conjuntoids_a_agregarque contiene solo los IDs que están enid_clientes_nuevospero no enid_clientes_actual.
- En este caso,
ids_a_agregarcontendrá{109, 110}ya que estos son los IDs únicos endata_nuevoque no se encuentran endata.
Paso 4: Filtrar las filas del nuevo DataFrame con los IDs únicos para agregar
Ahora, usamos el conjunto ids_a_agregar para filtrar data_nuevo y obtener solo las filas con los IDs que no están en el dataset original. Estas son las filas que vamos a agregar a data.

data_nuevo["ID Cliente"].isin(ids_a_agregar)devuelve una Serie booleana que indica si cada ID endata_nuevoestá enids_a_agregar.data_nuevo[data_nuevo["ID Cliente"].isin(ids_a_agregar)]filtradata_nuevoy devuelve solo las filas donde"ID Cliente"está enids_a_agregar.data_nuevo_filtradoahora contiene solo las filas con los IDs109y110, que son los nuevos datos que queremos agregar.
Paso 5: Concatenar ambos datasets
Finalmente, usamos pd.concat() para combinar el dataset original data con las filas filtradas en data_nuevo_filtrado.

pd.concat([data, data_nuevo_filtrado])concatenadataydata_nuevo_filtrado, agregando las filas dedata_nuevo_filtradoal final dedata.
ignore_index=Trueasegura que el índice del DataFrame resultante sea continuo y no conserve los índices originales dedata_nuevo_filtrado.
Paso 6: Verificar el dataset combinado
Finalmente, mostramos las primeras 15 filas del dataset data para verificar que las nuevas filas se hayan agregado correctamente.
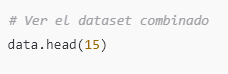
Este comando muestra las primeras 15 filas de data, permitiéndote verificar que los nuevos datos se hayan agregado al dataset original sin duplicar IDs existentes.
Intersección de dos conjuntos de datos
Si quieres ver los IDs comunes entre dos conjuntos de datos, puedes usar la intersección de conjuntos.
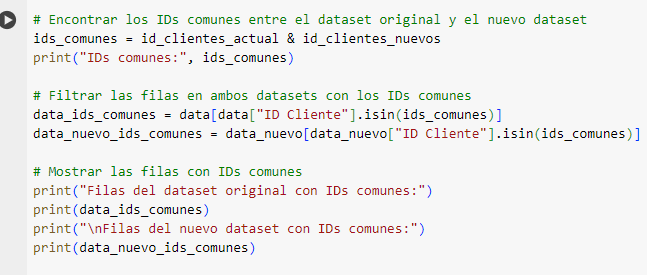
Explicacion del Codigo
Paso 1: Encontrar los IDs comunes entre los datasets
La primera línea de este fragmento de código usa la intersección de conjuntos para encontrar los IDs que están en ambos datasets.

id_clientes_actuales el conjunto de IDs únicos del dataset originaldata.id_clientes_nuevoses el conjunto de IDs únicos del nuevo datasetdata_nuevo.id_clientes_actual & id_clientes_nuevoscalcula la intersección de ambos conjuntos, devolviendo solo los IDs que están presentes en ambos.ids_comunescontendrá todos los IDs que aparecen en ambos datasets (IDs duplicados).
El print("IDs comunes:", ids_comunes) muestra los IDs comunes encontrados.
Paso 2: Filtrar las filas con los IDs comunes en ambos datasets
A continuación, usamos ids_comunes para filtrar solo las filas en data y data_nuevo que contienen esos IDs comunes.

Desglose de cada línea:
- Filtrar filas en el dataset original (
data):data["ID Cliente"].isin(ids_comunes): Esto genera una Serie booleana donde cada valor esTruesi el"ID Cliente"endataestá enids_comunesyFalseen caso contrario.data[data["ID Cliente"].isin(ids_comunes)]: Filtradatapara incluir solo las filas donde"ID Cliente"está enids_comunes.- El resultado se guarda en
data_ids_comunes, que contiene todas las filas del dataset original con IDs comunes.
- Filtrar filas en el nuevo dataset (
data_nuevo):data_nuevo["ID Cliente"].isin(ids_comunes): Similar al anterior, esto genera una Serie booleana para el nuevo datasetdata_nuevo.data_nuevo[data_nuevo["ID Cliente"].isin(ids_comunes)]: Filtradata_nuevopara incluir solo las filas donde"ID Cliente"está enids_comunes.- El resultado se guarda en
data_nuevo_ids_comunes, que contiene todas las filas del nuevo dataset con IDs comunes.
Paso 3: Mostrar las filas con IDs comunes
Finalmente, imprimimos las filas con IDs comunes en ambos datasets para comparar los datos.
print("Filas del dataset original con IDs comunes:"): Este mensaje indica que las filas siguientes pertenecen al dataset original (data).
print(data_ids_comunes): Imprime las filas dedatacon IDs comunes.
print("\nFilas del nuevo dataset con IDs comunes:"): Este mensaje indica que las filas siguientes pertenecen al nuevo dataset (data_nuevo).
print(data_nuevo_ids_comunes): Imprime las filas dedata_nuevocon IDs comunes.

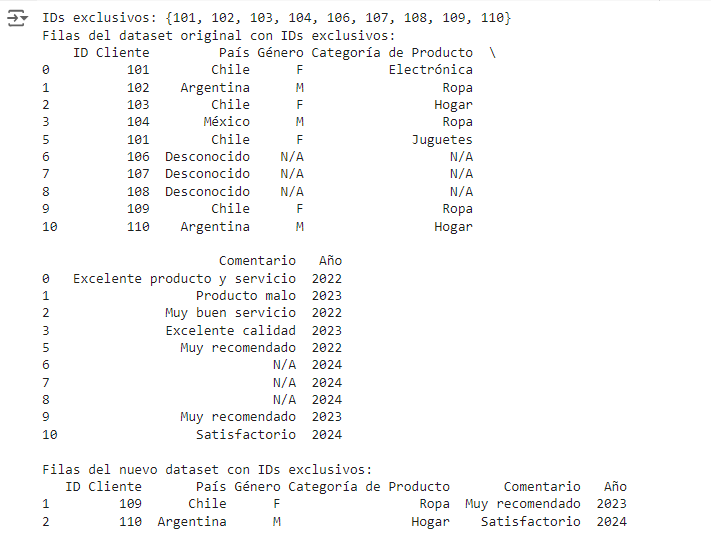
Diferencia simétrica para detectar exclusividad
La diferencia simétrica (^) nos permite encontrar IDs que están en uno de los datasets pero no en ambos, lo cual puede ser útil para detectar registros exclusivos en cada conjunto de datos.
Explicacion del Codigo
Paso 1: Encontrar los IDs exclusivos en cada dataset
La diferencia simétrica en conjuntos nos permite identificar los elementos que están en uno de los conjuntos, pero no en ambos. En este código, usamos la diferencia simétrica para encontrar los IDs de cliente que están exclusivamente en data o en data_nuevo, pero no en ambos.

id_clientes_actuales el conjunto de IDs únicos en el dataset originaldata.id_clientes_nuevoses el conjunto de IDs únicos en el nuevo datasetdata_nuevo.id_clientes_actual ^ id_clientes_nuevoscalcula la diferencia simétrica de ambos conjuntos. Esto significa queids_exclusivoscontendrá los IDs que están enid_clientes_actualo enid_clientes_nuevos, pero no en ambos.- La línea
print("IDs exclusivos:", ids_exclusivos)muestra los IDs que son exclusivos para cada dataset.
Paso 2: Filtrar las filas con los IDs exclusivos en ambos datasets
En este paso, usamos ids_exclusivos para filtrar solo las filas de data y data_nuevo que contienen esos IDs exclusivos.

Explicación de cada línea:
- Filtrar las filas en el dataset original (
data):data["ID Cliente"].isin(ids_exclusivos): Esto crea una Serie booleana en la que cada valor esTruesi el"ID Cliente"endataestá enids_exclusivosyFalseen caso contrario.data[data["ID Cliente"].isin(ids_exclusivos)]: Filtradatapara incluir solo las filas donde"ID Cliente"está enids_exclusivos.- El resultado se guarda en
data_ids_exclusivos, que contiene todas las filas del dataset original con IDs exclusivos.
- Filtrar las filas en el nuevo dataset (
data_nuevo):data_nuevo["ID Cliente"].isin(ids_exclusivos): Similar al anterior, esto genera una Serie booleana para el nuevo datasetdata_nuevo.data_nuevo[data_nuevo["ID Cliente"].isin(ids_exclusivos)]: Filtradata_nuevopara incluir solo las filas donde"ID Cliente"está enids_exclusivos.- El resultado se guarda en
data_nuevo_ids_exclusivos, que contiene todas las filas del nuevo dataset con IDs exclusivos.
Paso 3: Mostrar las filas con IDs exclusivos
Finalmente, imprimimos las filas con IDs exclusivos en ambos datasets para ver cuáles registros están presentes solo en un dataset y no en el otro.

print("Filas del dataset original con IDs exclusivos:"): Este mensaje indica que las filas que siguen pertenecen al dataset original (data) y tienen IDs exclusivos.print(data_ids_exclusivos): Imprime las filas dedatacon IDs exclusivos.print("\nFilas del nuevo dataset con IDs exclusivos:"): Este mensaje indica que las filas que siguen pertenecen al nuevo dataset (data_nuevo) y tienen IDs exclusivos.print(data_nuevo_ids_exclusivos): Imprime las filas dedata_nuevocon IDs exclusivos.