
Para manipulaciones y análisis de datos, Pandas y NumPy son las bibliotecas base. NumPy es ideal para operaciones matemáticas y estructurales en arreglos, mientras que Pandas sobresale en la organización, manipulación y limpieza de datos tabulares. Comenzar con estas dos te dará una base sólida en ciencia de datos, y te permitirá trabajar con prácticamente cualquier tipo de dato.
Vamos a ver algunas instrucciones para entender la utilidad de estas librerias, para eso utilizaremos un dataset de Kaggle.
Primero se debe instalar
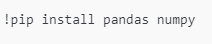
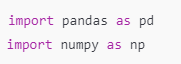
Una vez instaladas, puedes importarlas en tu código. La convención es importarlas usando alias (pd para Pandas y np para NumPy), lo cual es común en la comunidad de ciencia de datos.
Ahora a cargar el data set
Kaggle sugiere una ruta en Google Drive para asi poder trabajar en otros proyectos.
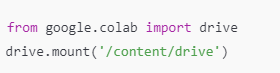
Este código se usa en Google Colab para montar Google Drive en el entorno. Esto permite que tengas acceso a todos tus archivos en Google Drive directamente desde Colab, lo cual es útil para cargar o guardar datasets. La función drive.mount('/content/drive') conecta tu Google Drive al sistema de archivos de Colab en la ubicación /content/drive.
Si necesitas montar nuevamente (por ejemplo, si hubo un error previo), puedes forzar el montaje usando:

Cambio de Directorio (%cd):

Esta línea cambia el directorio de trabajo actual a la carpeta especificada dentro de Google Drive, en este caso, My Drive/db. Usando %cd, puedes cambiar el directorio para trabajar en una carpeta específica, lo cual facilita el acceso a archivos sin tener que escribir la ruta completa cada vez.
- %cd: Es un comando de «magic» en Jupyter que permite cambiar el directorio de trabajo.
- ‘/content/drive/My Drive/db’: Es la ruta dentro de Google Drive a la que se cambia el directorio de trabajo.
Ahora, cualquier archivo que quieras cargar o guardar estará ubicado dentro de esta carpeta a menos que especifiques otra ruta.
Una vez que has montado Google Drive en Google Colab y has cambiado el directorio a una carpeta específica, puedes crear, leer, modificar y guardar archivos dentro de esa carpeta en Google Drive directamente desde Colab. Esto es útil porque permite trabajar de forma continua con archivos almacenados en la nube sin necesidad de descargarlos o subirlos manualmente cada vez.
Por ejemplo, en la carpeta /content/drive/My Drive/db (que has seleccionado como tu directorio actual), puedes:
Leer archivos: Cargar archivos que ya tienes en Google Drive, como datasets en formato CSV, Excel, imágenes, etc.
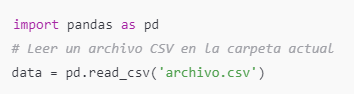
Crear y guardar archivos: Guardar nuevos archivos o resultados de tu trabajo en Google Drive. Cualquier archivo que guardes se almacenará en esa carpeta específica, por ejemplo:

Modificar archivos: Puedes modificar archivos existentes y luego volver a guardarlos, por ejemplo, después de hacer cambios en un DataFrame o después de procesar una imagen.
Acceder a subcarpetas: Si tienes subcarpetas dentro de /content/drive/My Drive/db, también puedes navegar y trabajar dentro de esas subcarpetas.
Ejemplo de Uso de Pandas para Análisis Básico
Resumen Estadístico:
Este código genera estadísticas básicas como la media, mínimo, máximo, y desvío estándar para cada columna numérica del dataset. Aquí tienes un resumen de algunos valores:
- Promedio de glucosa: ~120.89
- Promedio de presión sanguínea: ~69.11
- Promedio de BMI (Índice de Masa Corporal): ~31.99
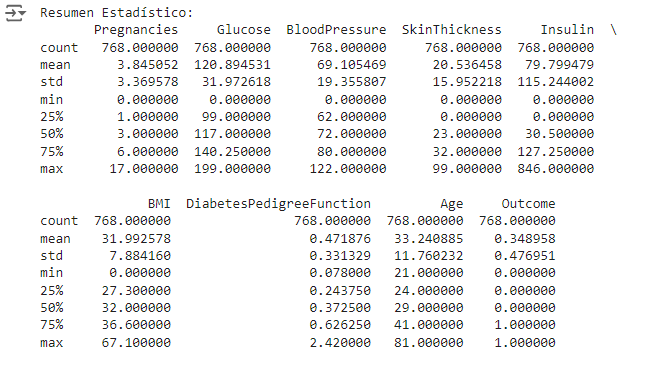
Esta tabla muestra estadísticas básicas de cada columna en el dataset. Veamos cada fila en detalle:
- count: Muestra el número de valores no nulos en cada columna. En este caso, todas las columnas tienen 768 valores, lo cual indica que no hay valores faltantes en este dataset.
- mean: La media aritmética de cada columna. Por ejemplo, el promedio de embarazos es 3.84, y el promedio de glucosa es 120.89.
- std: La desviación estándar, que mide la dispersión de los datos respecto a la media. Por ejemplo, la desviación estándar de la glucosa es 31.97, lo que indica variabilidad en los niveles de glucosa entre los pacientes.
- min y max: El valor mínimo y máximo en cada columna. Por ejemplo, el nivel mínimo de glucosa registrado es 0 (posiblemente indicando un valor faltante o erróneo), y el máximo es 199.
- 25%, 50% (mediana) y 75%: Los percentiles. Por ejemplo, el 25% de los pacientes tiene un nivel de glucosa de 99 o menos, el 50% tiene 117 o menos, y el 75% tiene 140.25 o menos. Esto es útil para entender la distribución de los datos.
Conteo de Valores en ‘Outcome’

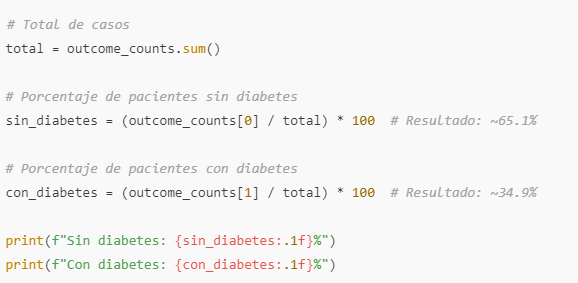
Esta sección muestra la cantidad de casos positivos y negativos para diabetes en la columna Outcome:
- 0: 500 pacientes sin diabetes.
- 1: 268 pacientes con diabetes.
Esto significa que aproximadamente el 34.9% de los pacientes tienen diabetes, mientras que el 65.1% no la tienen. Esto indica que los datos están desbalanceados, algo que puede influir en el análisis y en los modelos de machine learning.


Codigo de Calculos de porcentages
Nota:
Este código utiliza f-strings en Python, una forma de crear cadenas de texto (strings) que permite incrustar expresiones dentro de llaves {} para que se evalúen y se incluyan en la cadena. Veamos cada parte del código en detalle:
- f-string (
f"..."):- Al colocar una f antes de las comillas dobles o simples (
f"..."of'...'), se indica a Python que esta es una f-string. - Una f-string permite insertar variables y expresiones directamente dentro de la cadena de texto, encerrándolas en llaves
{}.
- Al colocar una f antes de las comillas dobles o simples (
- Texto de la Cadena:
"Sin diabetes: "y"Con diabetes: "son textos normales que aparecen en la salida para dar contexto. Estos textos indican los porcentajes correspondientes a cada categoría.
- Incrustación de Variables en
{}:{sin_diabetes}y{con_diabetes}: Estas son las variables que contienen los valores de los porcentajes calculados anteriormente. Al incluirlas en{}, Python reemplaza el marcador con el valor de la variable.
- Formato
.1fdentro de{}:.1fes una especificación de formato que indica cómo se debe mostrar el valor numérico:- .1: Representa el número de decimales que queremos mostrar. En este caso,
.1significa que se mostrará un solo decimal. - f: Significa que el valor debe ser formateado como un número de punto flotante (decimal).
- .1: Representa el número de decimales que queremos mostrar. En este caso,
- En resumen,
{sin_diabetes:.1f}formatea el valor desin_diabetespara que aparezca con un decimal. Por ejemplo, si el valor desin_diabeteses 65.104, se mostrará como 65.1.
- Símbolo
%al final:- El símbolo
%fuera de las llaves es simplemente parte del texto. No tiene ninguna función especial en este contexto y solo se usa para indicar que el valor es un porcentaje.
- El símbolo
Este formato es muy útil para controlar la precisión de los valores numéricos que se muestran en los resultados.
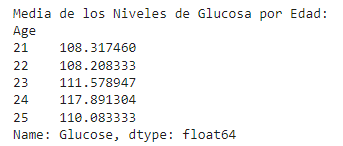
Media de los Niveles de Glucosa por Edad

En esta sección, agrupamos los datos por edad y calculamos el nivel promedio de glucosa para cada grupo de edad. Los valores mostrados son ejemplos para las edades de 21 a 25:
- Edad 21: Promedio de glucosa de 108.32
- Edad 22: Promedio de glucosa de 108.21
- Edad 23: Promedio de glucosa de 111.58
- Edad 24: Promedio de glucosa de 117.89
- Edad 25: Promedio de glucosa de 110.08
Esto te permite ver cómo varía el nivel promedio de glucosa en diferentes grupos de edad, lo cual puede ser útil para identificar patrones relacionados con la edad.

Interpretación General
Este análisis inicial nos da una idea de la estructura y características del dataset:
- Existen algunos valores mínimos de 0 en columnas como Glucose, BloodPressure, SkinThickness, Insulin, y BMI. Esto podría indicar datos faltantes o incorrectos, ya que en un contexto médico estos valores deberían ser mayores a cero.
- Los datos están desbalanceados en la columna Outcome, lo que puede requerir técnicas específicas para el análisis de machine learning, como muestreo o ponderación.
- Hay una variabilidad notable en los niveles de glucosa y otros indicadores, lo que podría ser interesante explorar en estudios adicionales.
Explicacion del codigo

Este código agrupa el dataset por la columna Age (edad) y calcula el promedio de Glucose (glucosa) para cada grupo de edad. El resultado es una serie de Pandas donde cada índice es una edad y cada valor es el nivel promedio de glucosa para esa edad.

El método .head() en Pandas devuelve solo las primeras 5 filas de un objeto (puedes especificar otro número si deseas más o menos filas). En este caso, usamos .head() para mostrar únicamente los primeros resultados, ya que el dataset podría contener muchas edades diferentes. Si se imprimieran todas, la salida podría ser demasiado extensa y difícil de leer.
- Propósito:
.head()es útil cuando solo quieres revisar una parte del resultado, especialmente en datasets grandes. - Ejemplo: Si
mean_glucose_by_agecontiene los niveles promedio de glucosa para 30 edades,mean_glucose_by_age.head()mostrará solo los valores de las primeras 5 edades.
Por qué Mostrar Solo los Primeros Resultados La razón de usar .head() aquí es para evitar saturar la salida con demasiada información. Esto es común en análisis de datos, ya que muchas veces solo necesitas ver una muestra pequeña para verificar que el código funciona correctamente, sin necesidad de visualizar todo el conjunto de datos.
Si quieres ver todos los niveles de glucosa promedio por edad sin limitar la salida, simplemente quita .head()

